
Blogs / Cloud Consulting
What is Data Lakehouse? How Does It Work
By
Harish K K [CTO]
Posted: May 05, 2025
• 8 Minutes




The Evolution of Data Management: From Data Warehouses to Data Lakehouses
Data Warehouse:
A Data Warehouse is a centralized system designed for storing, organizing, and analyzing structured data from multiple sources. It follows a predefined schema, ensuring data is clean, consistent, and optimized for business intelligence (BI) and reporting.
Data Lake:
A Data Lake is a large, flexible storage system that holds raw, unstructured, semi-structured, and structured data in its native format. It allows businesses to store vast amounts of data without structuring it upfront.
The earlier data management systems have evolved significantly to meet the growing need for scalable, efficient, and analytics-ready solutions. Initially, Data Warehouses served as centralized repositories for structured data, enabling organizations to analyze historical information from multiple sources and get valuable business insights. However, data warehouses have inherent limitations, including proprietary storage formats that create vendor lock-in and constraints in handling advanced analytical workloads, particularly those involving unstructured data such as machine learning models.
To overcome these challenges, Data Lakes emerged as a scalable alternative, allowing organizations to store structured, semi-structured, and unstructured data in cost-efficient storage solutions. By separating storage from computing, data lakes provide more scalability, flexibility in data processing, and cost efficiency in resource management. They also use open file formats like Apache Parquet and Apache ORC, making data easier to access and process. Despite these advantages, data lakes introduce their challenges, such as a lack of transactional integrity (ACID compliance), governance complexities, and data quality issues, making it difficult to generate reliable, analytics-ready insights.
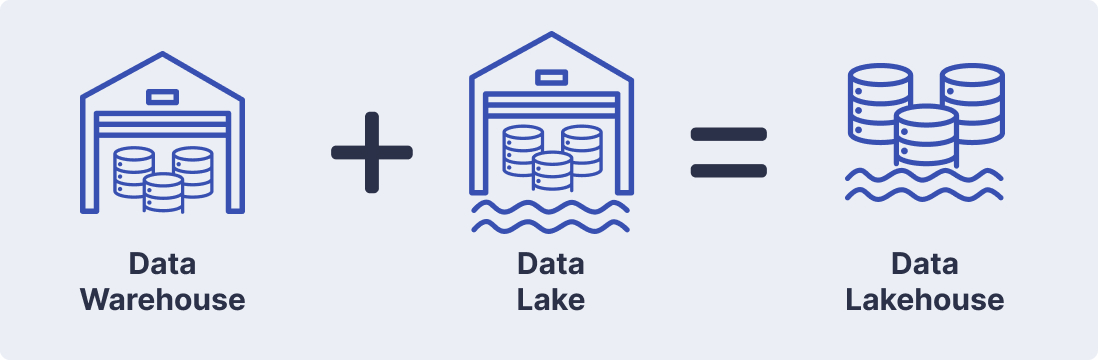
The need for a more unified and efficient solution led to the emergence of Data Lakehouse architecture. A Lakehouse integrates the best features of Data Warehouses and Data Lakes, offering both structured data management and scalable storage. Let’s understand what Data Lakehouse is and how it differs from traditional data management systems.
What is Data Lakehouse?
A Data Lakehouse is a hybrid data storage and management architecture that combines the strengths of both Data Warehouses and Data Lakes. It allows organizations to store and manage structured, semi-structured, and unstructured data in one centralized system.
The following key features make Data Lakehouse an ideal solution for modern data management needs.
Key Features of Data Lakehouse
- Flexible Deployment: Can be deployed on-premises or in the cloud, allowing organizations to choose the best infrastructure for their needs.
- High-Performance Analytics: Supports fast querying and real-time data processing, enabling efficient analysis of large datasets.
- Open Storage Formats: Supports standardized, non-proprietary file formats to provide flexible, scalable, and cost-efficient data management.
- Seamless Data Integration: Combines structured and unstructured data in a unified system, eliminating data silos and reducing duplication.
- Strong Governance & Security: Implements data governance, access controls, and compliance policies to maintain data integrity and security.
Let’s explore how the features of a Data Lakehouse differ from those of traditional data management systems like Data Warehouses and Data Lakes.
The Data Lakehouse Architecture: Understanding Its Core Components and Workflow
To fully grasp the Data Lakehouse architecture, it’s crucial to understand how its core layers work together as a seamless workflow. The architecture follows a structured data lifecycle, from ingestion to consumption, ensuring scalability, governance, and high-performance analytics. Let’s break down its core layers and their roles in Lakehouse architecture.
Data Lakehouse Architecture
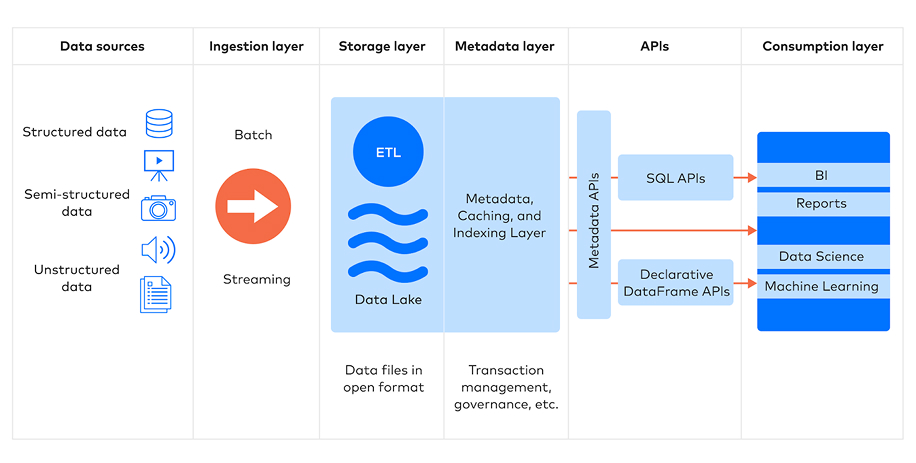
Core Layers of Data Lakehouse Architecture and Their Functions
-
Data Ingestion Layer
This layer is responsible for collecting and delivering data. It captures data from various structured, semi-structured, and unstructured sources, including:
- Databases – Relational (SQL-based) & NoSQL systems
- Enterprise Applications – ERP, CRM, SaaS platforms
- Event Streams – IoT sensor data, real-time logs, clickstreams
- Files & External Sources – CSV, JSON, images, videos, and more
How It Works:
- Data is pulled or pushed from these sources into the storage layer.
- The ingestion system supports both batch and real-time streaming methods.
- The data pipeline may also include data normalization, deduplication, and compaction before storage.
-
Data Processing Layer – Transforming & Preparing Data
This layer processes raw data and converts them into an analytics-ready format, supporting:
- ETL (Extract, Transform, Load) & ELT (Extract, Load, Transform) operations
- Big Data Processing using frameworks like Apache Spark, Flink, and Presto
- Schema-on-read and schema-on-write for flexible transformations
How It Works:
- Data cleaning, normalization, enrichment, and aggregation occur in this layer.
- Supports both batch and real-time processing, ensuring quick insights for business users.
- Workflows are optimized for performance with in-memory caching and parallel computing.
-
Data Storage Layer
This layer provides a scalable, cost-effective, and unified storage repository for all data types, including:
- Raw unstructured files – Images, videos, documents
- Semi-structured data – JSON, XML, Parquet
- Structured tables – SQL-based transactional data
How It Works:
- Stores and organizes data for efficient management and faster querying using open table formats like Delta Lake, Apache Iceberg, or Apache Hudi.
- Decouple storage from computing, allowing for independent scaling and optimized cost management.
- Data schemas are registered and managed in the metadata layer, ensuring governance while maintaining flexibility.
-
Metadata & Governance Layer
This layer serves as the data catalogue that organizes and manages data, enabling users to:
- Track data lineage, indexing, and schema evolution
- Implement governance policies (data access, permissions)
- Maintain ACID transactions (Atomicity, Consistency, Isolation, Durability)
How It Works:
- The metadata layer ensures data versioning, allowing users to track changes and rollback when needed.
- Schema enforcement and indexing optimize data retrieval and query performance.
- Audit logs & governance tools enhance compliance with regulations like GDPR, HIPAA, and SOC 2.
-
Query & API Layer – Accessing Data via SQL & Programming Interfaces
This layer provides APIs and query engines by accessing Data via SQL & Programming Interfaces to enable diverse workloads, including:
- SQL-based querying – Business intelligence, reporting, ad-hoc analysis
- DataFrame APIs (Python, R, Scala, Java) – For data science & machine learning
- Real-time querying & caching – For low-latency applications
How It Works:
- BI analysts can use SQL for quick analysis, while data scientists can work with Python/R for deeper analytics.
- APIs provide seamless access to data, enabling integration with external tools.
- Federated query engines allow queries to run across both structured and unstructured data.
-
Data Consumption Layer
At the final stage, transformed and enriched data is made available for end-users delivering Insights to Business & AI Systems via:
- Business Intelligence (BI) Tools – Tableau, Power BI, Looker
- Data Science & AI/ML Applications – TensorFlow, Scikit-Learn, PyTorch
- Operational Dashboards & Embedded Analytics – Real-time decision-making
How It Works:
- Users can generate interactive dashboards, reports, and AI models from the lakehouse.
- The unified storage and metadata ensure consistency across all analytics workflows.
- Machine Learning models can directly access curated datasets, improving efficiency.
How Data Lakehouse Addresses the Limitations of Data Warehouses and Data Lake
-
Addresses Scalability & Cost Limitations of Data Warehouses
- A Data Lakehouse stores raw structured, semi-structured, and unstructured data in low-cost unified cloud storage – such as Amazon S3, Azure Data Lake, or Google Cloud Storage.
- Different from traditional data warehouses that rely on proprietary, high-cost storage, Data Lakehouses use open file formats that are optimized for big data processing.
- This ensures high scalability without the high costs associated with warehouse solutions.
-
Solves Governance & Schema Management Issues in Data Lakes
- Data Lakehouses maintain a centralized metadata and catalog layer such as Apache Hive Metastore, AWS Glue, or Unity Catalog.
- Unlike raw data lakes, this layer enforces schema tracking, versioning, and partitioning, making data more structured and accessible.
- It enables schema evolution, meaning new data can be added without breaking existing queries.
-
Eliminates Slow Query Performance in Data Lakes
- Data Lakehouses use query acceleration technologies like indexing, caching, and query optimization (e.g., Databricks Photon, Presto, or Trino).
- Columnar storage formats like Parquet and ORC enhance query performance by allowing only relevant data to be read.
- Native support for SQL-based querying enables analysts to run fast, structured queries across massive datasets.
-
Fixes Data Consistency Issues in Data Lakes
- Using Delta Lake, Apache Iceberg, or Apache Hudi, Data Lakehouses implement ACID (Atomicity, Consistency, Isolation, Durability) transactions.
- These ensure that concurrent read/write operations don’t lead to data corruption or inconsistencies - something that traditional data lakes struggle with.
- It supports time-travel and rollback functionality, allowing organizations to revert to previous states of data.
-
Unifying BI & AI/ML Workloads in Data Warehouses and Data Lakes
- Traditional data warehouses focus on structured, SQL-based analytics, while data lakes support AI/ML and big data workloads.
- A Data Lakehouse supports multi-modal processing by enabling SQL-based BI tools (Tableau, Power BI) alongside AI/ML frameworks (TensorFlow, PyTorch, Scikit-Learn).
- Data scientists can directly query raw and processed data without needing to extract it into separate systems.
-
Addressing Latency Issues in Data Warehouses
- Data Lakehouse ingests data in real time via Apache Kafka, AWS Kinesis, or Azure Event Hubs.
- Batch processing is handled using Apache Spark or Flink, ensuring efficient ETL and data transformation.
- This real-time capability allows for instant analytics on live streaming data while maintaining batch-processing efficiency.
-
Enables Data Consistency Issues in Data Lakes
- Unlike traditional data lakes, a Data Lakehouse supports MERGE, UPDATE, and DELETE operations.
- Enables Change Data Capture (CDC) and Slowly Changing Dimensions (SCD), crucial for businesses handling dynamic datasets.
- Uses transaction logs to maintain data consistency across updates, making corrections and historical tracking easier.
-
Reduce Vendor lock-ins seen in warehouses via Open-Source & Cloud Integration
- Data Lakehouse supports open-source formats (Apache Parquet, Delta Lake, Iceberg, Hudi) for vendor-agnostic compatibility.
- It can be implemented in on-premises, hybrid, and multi-cloud environments.
- Can be integrated with the cloud via modern cloud-based Lakehouse solutions such as Databricks, AWS Lake Formation, Google BigQuery, and Azure Synapse.
How a Data Lakehouse Benefits Your Business
Adopting a Data Lakehouse can transform the way your business manages and analyzes data by providing a cost-effective, scalable, and high-performance solution tailored to modern business needs. Here’s how it can benefit you:
- Reduce Costs and Maximize Efficiency: With a Lakehouse, you no longer need expensive proprietary storage or separate systems for structured and unstructured data. Instead, you leverage low-cost cloud object storage and a pay-as-you-go model, significantly reducing infrastructure and operational costs. This means you only pay for what you use, optimizing your data management expenses.
- Seamlessly Scalability as Your Business Grows: As your data volumes expand, Lakehouse allows you to scale storage and compute resources independently. Unlike traditional architecture that requires costly upgrades, a Lakehouse automatically adjusts to meet growing demands, ensuring smooth performance even as workloads become more complex.
- Simplify Your Data Architecture and Eliminate Silos: Managing multiple data storage systems often leads to data duplication, inefficiencies, and integration headaches. With a lakehouse, everything is stored in a single repository, eliminating unnecessary data movement and reducing complexity. This makes it easier for analysts, engineers, and data scientists to access and analyze data without unnecessary delays.
- Enable Real-Time and Advanced Analytics: Whether you need instant insights from live data streams or deep analytical processing, a lakehouse supports both real-time and batch analytics. This means your business can act faster on market trends, customer behavior, and operational metrics, giving you a competitive edge in industries that rely on rapid decision-making.
- Ensure High-Quality, Governed Data for Better Decision-Making: A lakehouse enforces schema validation, data integrity, and access controls, ensuring that your data is accurate, secure, and compliant with regulations like GDPR and HIPAA. With built-in governance features, you can confidently provide trusted, high-quality data to your analysts, data scientists, and executives.
Who Needs Data Lakehouse: Understanding Its Comprehensive Use Cases
The data lakehouse is not just a solution for tech giants or data-intensive industries; it is a versatile platform that can empower organizations of all sizes and sectors. Below are some of the most impactful use cases where Data Lakehouses drive measurable business outcomes.
-
Advanced Analytics & Predictive Insights
Helps businesses analyze diverse data types (structured and unstructured) to extract deeper insights, forecast demand, and optimize decision-making.
Applications:
- Retail: Analyze shopping trends for personalized recommendations.
- Finance: Detect fraudulent transactions in real time.
- Manufacturing: Optimize supply chain management with predictive analytics.
-
Real-Time Reporting & Dashboards
Enables real-time data streaming for instant monitoring, trend analysis, and informed decision-making.
Applications:
- E-commerce:xx Track sales performance and customer behavior.
- Finance: Analyze market trends for investment decisions.
- Healthcare: Monitor patient vitals and medical records.
-
Agile Data Exploration & Self-Service Analytics
Empowers analysts and business users to explore datasets, uncover trends, and make data-driven decisions independently.
Applications:
- Marketing: Analyze customer sentiment from social media.
- Product Teams: Assess feature usage for product development.
- Sales: Generate reports for sales forecasting.
-
IoT Data Processing & Predictive Maintenance
Handles large-scale, real-time IoT data streams to detect issues, improve performance, and optimize asset management.
Applications:
- Manufacturing: Monitor equipment health and predict maintenance needs.
- Smart Cities: Analyze traffic data for urban planning.
- Energy & Utilities: Track power grid performance and detect failures.
-
Regulatory Compliance & Data Governance
Ensures robust data governance, security, and compliance with legal and industry regulations.
Applications:
- Finance: Maintain SEC, GDPR, and SOX compliance.
- Healthcare: Ensure HIPAA-compliant patient data management.
- Government: Protect sensitive citizen information with encryption.
-
Data Monetization & Data-as-a-Service (DaaS)
Enables businesses to refine, process, and analyze data for monetization and strategic decision-making.
Applications:
- Market Research Firms: Sell industry trend reports
- Advertising Companies: Use consumer behavior analytics for targeted ads.
- Financial Services: Provide market intelligence insights to investors.
Popular Data Lakehouse Platforms for Businesses
Several leading platforms offer Data Lakehouse solutions, providing organizations with scalability, governance, real-time analytics, and AI/ML support. Below are some of the most popular Data Lakehouse platforms:
- Databricks Lakehouse: Built on Apache Spark and Delta Lake, Databricks provides an open and unified platform for data engineering, analytics, and AI/ML workloads.
- Snowflake Data Cloud: A cloud-based data platform that supports Lakehouse capabilities by integrating structured and semi-structured data.
- Google BigQuery: Google’s serverless data warehouse with built-in ML and real-time analytics capabilities.
- Amazon Redshift Spectrum: Amazon Redshift extends data warehouse capabilities to query S3 Data Lakes using SQL-based analytics.
- Microsoft Azure Synapse Analytics: Azure’s Lakehouse platform integrates big data and enterprise analytics with SQL, Spark, and ML support.
- Apache Iceberg: An open-source table format for large-scale analytics, used by companies like Netflix, LinkedIn, and Apple.
- Apache Hudi: An open-source Lakehouse framework designed for real-time data ingestion and incremental processing.
- IBM Watsonx.data: IBM’s Lakehouse solution for AI-powered analytics and governance.
Choosing the Right Data Lakehouse Platform with Gsoft
All these Data Lakehouse platforms can eliminate traditional challenges such as data silos, high storage costs, slow query performance, and governance issues. This makes it an ideal solution for businesses looking to leverage AI, machine learning, and real-time analytics.
Not all businesses require Data Lakehouse integration. As a trusted cloud service provider and a partner of AWS, Azure, and Google Cloud, Gsoft helps businesses determine whether a Data Lakehouse is the right solution for their needs. We also recognize that choosing and implementing the right platform can be complex. Since every business has unique data requirements, selecting the best solution demands expert insights, strategic planning, and seamless integration with existing cloud infrastructure.
Does your business need to integrate a Data Lakehouse platform? Our team of certified cloud consultants can help you:
- Assess your current data infrastructure and identify the best Lakehouse solution for your business
- Guide you through seamless migration and integration with AWS, Azure, or GCP.
- Optimize your cloud costs, governance, and security for a scalable, future-proof data strategy.
Get in touch with us today for a free consultation and take the next step toward modernizing your data architecture! Contact us!





Get Know More About Our Services and Products
Reach to us if you have any queries on any of our products or Services.



